1、数据库ORM技术
引子:使用SQLAlchemy - Python教程 - 廖雪峰的官方网站
ORM(Object-Relational Mapping)把关系数据库的表结构映射到对象上
数据库表是一个二维表,包含多行多列。把一个表的内容用Python的数据结构表示出来的话,可以用一个list表示多行,list的每一个元素是tuple,表示一行记录,比如,包含id和name的user表:
[
('1', 'Michael'),
('2', 'Bob'),
('3', 'Adam')
]
但是用tuple表示一行很难看出表的结构。如果把一个tuple用class实例来表示,就可以更容易地看出表的结构来:
class User(object):
def __init__(self, id, name):
self.id = id
self.name = name
[
User('1', 'Michael'),
User('2', 'Bob'),
User('3', 'Adam')
]
这就是传说中的ORM技术:Object-Relational Mapping,把关系数据库的表结构映射到对象上。是不是很简单?
但是由谁来做这个转换呢?所以ORM框架应运而生。
在Python中,最有名的ORM框架是SQLAlchemy。我们来看看SQLAlchemy的用法。
首先通过pip安装SQLAlchemy: pip install sqlalchemy
然后,利用上次我们在MySQL的test数据库中创建的user表,用SQLAlchemy来试试:
第一步,导入SQLAlchemy,并初始化DBSession:
# 导入:
from sqlalchemy import Column, String, create_engine
from sqlalchemy.orm import sessionmaker
from sqlalchemy.orm import declarative_base
# 创建对象的基类,都要继承该类:
Base = declarative_base()
# 定义User对象:
class User(Base):
# 表的名字:
__tablename__ = 'user'
# 表的结构:
id = Column(String(20), primary_key=True)
name = Column(String(20))
# 初始化数据库连接:
engine = create_engine('mysql+mysqlconnector://root:password@localhost:3306/test')
# 创建DBSession类型:
DBSession = sessionmaker(bind=engine)
create_engine()用来初始化数据库连接。SQLAlchemy用一个字符串表示连接信息:
'数据库类型+数据库驱动名称://用户名:口令@机器地址:端口号/数据库名'你只需要根据需要替换掉用户名、口令等信息即可。
下面,我们看看如何向数据库表中添加一行记录。
由于有了ORM,我们向数据库表中添加一行记录,可以视为添加一个User对象:
# 创建session对象:
session = DBSession()
# 创建新User对象:
new_user = User(id='5', name='Bob')
# 添加到session:
session.add(new_user)
# 提交即保存到数据库:
session.commit()
# 关闭session:
session.close()可见,关键是获取session,然后把对象添加到session,最后提交并关闭。DBSession对象可视为当前数据库连接。
如何从数据库表中查询数据呢?有了ORM,查询出来的可以不再是tuple,而是User对象。SQLAlchemy提供的查询接口如下:
# 创建Session:
session = DBSession()
# 创建Query查询,filter是where条件,最后调用one()返回唯一行,如果调用all()则返回所有行:
user = session.query(User).filter(User.id=='5').one()
# 打印类型和对象的name属性:
print('type:', type(user))
print('name:', user.name)
# 关闭Session:
session.close()
# type: <class '__main__.User'>
# name: Bob可见,ORM就是把数据库表的行与相应的对象建立关联,互相转换。
由于关系数据库的多个表还可以用外键实现一对多、多对多等关联,相应地,ORM框架也可以提供两个对象之间的一对多、多对多等功能。
例如,如果一个User拥有多个Book,就可以定义一对多关系如下:
class User(Base):
__tablename__ = 'user'
id = Column(String(20), primary_key=True)
name = Column(String(20))
# 一对多:
books = relationship('Book')
class Book(Base):
__tablename__ = 'book'
id = Column(String(20), primary_key=True)
name = Column(String(20))
# “多”的一方的book表是通过外键关联到user表的:
user_id = Column(String(20), ForeignKey('user.id'))当我们查询一个User对象时,该对象的books属性将返回一个包含若干个Book对象的list。
2、FastChat模型管理
FastChat 作为轻量级 LLM 服务框架,其模型管理能力是实现 “多模型统一部署、灵活调度与高效推理” 的核心,涵盖模型支持范围、部署架构、加载配置、调度策略及个性化扩展等关键环节,以下从六大维度系统梳理。
2.1 支持模型范围:覆盖主流开源 LLM
FastChat 通过原生适配与灵活扩展,支持国内外 70 + 种主流开源大语言模型,满足不同场景的推理需求,具体可分为 “官方原生支持” 与 “非官方扩展支持” 两类:
1. 官方原生支持模型
涵盖 Meta、阿里、字节、清华等机构的主流模型,无需额外适配即可直接加载,核心模型及兼容性要求如下表:
2. 非官方扩展支持
对于 Hugging Face 上支持AutoModelForCausalLM的任意模型,可通过--model-path参数指定模型路径(本地路径或 HF 仓库地址)实现加载,例如:
bash
# 加载Hugging Face非官方模型(如Baichuan-13B)
python3 -m fastchat.serve.model_worker --model-path baichuan-inc/Baichuan-13B-Chat
扩展适配仅需在model_adapter.py中补充 “模型对话模板” 与 “Tokenizer 处理逻辑”,即可支持自定义模型的多轮对话格式。
二、模型部署架构:控制器 - 工作器分布式模式
FastChat 采用 “控制器(Controller)+ 模型工作器(Model Worker)” 的分布式架构,实现模型与服务解耦,支持多模型并行部署与动态调度,核心架构如下:
1. 核心组件分工
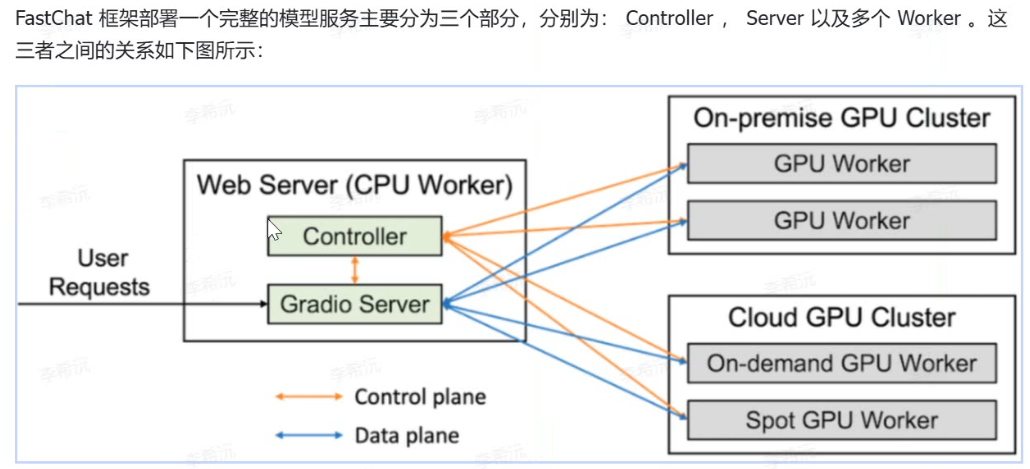
2. 部署流程:三步启动多模型服务
需按 “Controller→Model Worker→Web/API 服务” 的顺序启动,确保组件间通信正常:
启动控制器:初始化调度中心,默认监听
127.0.0.1:21001bash
python3 -m fastchat.serve.controller启动模型 Worker:加载目标模型,每个 Worker 对应一个独立模型(支持多卡并行)
bash
# 单GPU加载Vicuna-7B python3 -m fastchat.serve.model_worker --model-path lmsys/vicuna-7b-v1.5 # 多GPU(2卡)加载Qwen-14B,限制单卡内存8GiB python3 -m fastchat.serve.model_worker --model-path qwen/Qwen-14B-Chat --num-gpus 2 --max-gpu-memory 8GiB启动服务入口:选择 Web UI 或 API 服务,对外提供交互能力
bash
# 启动Gradio Web UI(用于可视化测试) python3 -m fastchat.serve.gradio_web_server # 启动OpenAI兼容API服务(用于企业级调用) python3 -m fastchat.serve.openai_api_server --port 8000
三、模型加载配置:适配不同硬件与性能需求
FastChat 提供细粒度加载配置,支持 CPU/GPU/vLLM 等不同硬件环境,兼顾 “显存占用” 与 “推理速度”,核心配置参数如下:
1. 硬件适配参数
2. 性能优化配置
vLLM 加速:与 vLLM 推理引擎深度兼容,通过
--backend vllm启用,可提升吞吐 3-10 倍,适合高并发 API 服务:bash
python3 -m fastchat.serve.model_worker --model-path lmsys/vicuna-7b-v1.5 --backend vllm长上下文适配:针对 LongChat、LLaMA 2-70B 等长上下文模型,需指定
--context-length参数,例如:bash
# 适配32k长上下文 python3 -m fastchat.serve.model_worker --model-path lmsys/longchat-7b-32k-v1.5 --context-length 32768
四、模型调度策略:动态切换与负载均衡
FastChat 通过 Controller 实现多模型的 “统一入口、动态调度”,支持按请求指定模型、自动负载均衡及故障转移,核心策略如下:
1. 模型指定方式
请求体指定:API 调用时通过
model字段指定目标模型,与 OpenAI API 完全兼容:json
// 调用ChatGLM3模型的API请求示例 POST /v1/chat/completions { "model": "chatglm3", "messages": [{"role": "user", "content": "介绍FastChat"}], "stream": true }全局默认模型:启动 Worker 时通过
--served-model-name指定对外暴露的模型名,适合固定模型服务:bash
python3 -m fastchat.serve.model_worker --model-path chatglm3-6b --served-model-name my-chatglm3
2. 多模型负载均衡
当部署多个 Worker(对应不同模型或同模型多实例)时,Controller 自动实现:
请求分发:按 Worker 负载(CPU/GPU 使用率)分配请求,避免单 Worker 过载;
故障转移:若某 Worker 异常下线,Controller 自动将请求路由至其他可用 Worker;
动态扩容:新增 Worker 时,无需重启 Controller,Worker 会自动注册至 Controller,支持运行时热扩容。
五、模型版本与生命周期管理
FastChat 支持模型的 “版本区分、热更新与资源释放”,满足企业级服务的迭代与维护需求:
1. 模型版本管理
版本区分:通过模型路径或服务名区分版本,例如
lmsys/vicuna-7b-v1.5与lmsys/vicuna-7b-v1.1可同时部署,通过model字段指定调用;微调模型加载:加载微调后的模型时,仅需指定微调后的 HF 仓库或本地路径,例如:
bash
# 加载微调后的Vicuna模型 python3 -m fastchat.serve.model_worker --model-path ./fine-tuned-vicuna-7b
2. 模型热更新与资源释放
热更新:替换模型时,无需停止 Controller 与 API 服务,仅需重启对应 Worker:
bash
# 停止旧模型Worker(假设PID为1234) kill 1234 # 启动新模型Worker python3 -m fastchat.serve.model_worker --model-path lmsys/vicuna-13b-v1.5资源释放:Worker 进程退出时自动释放 GPU/CPU 资源,也可通过
--max-batch-size限制单 Worker 并发,避免资源占用过高。
六、个性化扩展:自定义模型适配
对于特殊格式或小众模型,FastChat 支持通过修改代码实现适配,核心步骤如下:
1. 新增模型对话模板
在fastchat/conversation.py中添加模型专属对话格式(如自定义角色、多轮历史处理),示例:
python
# 为自定义模型添加对话模板
class MyModelConversation(Conversation):
def __init__(self):
super().__init__(
name="my-model",
system_template="你是专业的技术助手:{system_message}",
roles=("用户", "助手"),
sep="\n",
)
2. 实现模型适配器
在fastchat/model_adapter.py中补充模型加载逻辑(如 Tokenizer 特殊处理、模型权重映射):
python
# 自定义模型适配器
class MyModelAdapter(BaseModelAdapter):
def match(self, model_path: str):
return "my-model" in model_path # 匹配模型路径
def load_model(self, model_path: str, **kwargs):
# 自定义模型加载逻辑(如加载特殊Tokenizer)
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(model_path, **kwargs)
return model, tokenizer
3. 注册模型
在fastchat/model_registry.py中注册模型信息,确保 Controller 能识别:
python
# 注册自定义模型
model_info = {
"my-model-7b": {
"name": "my-model-7b",
"chat_template": "my-model", # 关联对话模板
"adapter": "MyModelAdapter", # 关联适配器
}
}3、Python并行开发
3.1 多进程
要让Python程序实现多进程(multiprocessing),我们先了解操作系统的相关知识。
Unix/Linux操作系统提供了一个fork()系统调用,它非常特殊。普通的函数调用,调用一次,返回一次,但是fork()调用一次,返回两次,因为操作系统自动把当前进程(称为父进程)复制了一份(称为子进程),然后,分别在父进程和子进程内返回。
子进程永远返回0,而父进程返回子进程的ID。这样做的理由是,一个父进程可以fork出很多子进程,所以,父进程要记下每个子进程的ID,而子进程只需要调用getppid()就可以拿到父进程的ID。
Python的os模块封装了常见的系统调用,其中就包括fork,可以在Python程序中轻松创建子进程:
import os
print('Process (%s) start...' % os.getpid())
# Only works on Unix/Linux/macOS:
pid = os.fork()
if pid == 0:
print('I am child process (%s) and my parent is %s.' % (os.getpid(), os.getppid()))
else:
print('I (%s) just created a child process (%s).' % (os.getpid(), pid))输出:
Process (876) start...
I (876) just created a child process (877).
I am child process (877) and my parent is 876.有了fork调用,一个进程在接到新任务时就可以复制出一个子进程来处理新任务,常见的Apache服务器就是由父进程监听端口,每当有新的http请求时,就fork出子进程来处理新的http请求。
multiprocessing
如果你打算编写多进程的服务程序,Unix/Linux无疑是正确的选择。由于Windows没有fork调用,难道在Windows上无法用Python编写多进程的程序?
由于Python是跨平台的,自然也应该提供一个跨平台的多进程支持。multiprocessing模块就是跨平台版本的多进程模块。
multiprocessing模块提供了一个Process类来代表一个进程对象,下面的例子演示了启动一个子进程并等待其结束:
from multiprocessing import Process
import os
# 子进程要执行的代码
def run_proc(name):
print('Run child process %s (%s)...' % (name, os.getpid()))
if __name__=='__main__':
print('Parent process %s.' % os.getpid())
p = Process(target=run_proc, args=('test',))
print('Child process will start.')
p.start()
p.join()
print('Child process end.')
"""
Parent process 928.
Child process will start.
Run child process test (929)...
Process end.
"""创建子进程时,只需要传入一个执行函数和函数的参数,创建一个Process实例,用start()方法启动,这样创建进程比fork()还要简单。
join()方法可以等待子进程结束后再继续往下运行,通常用于进程间的同步。
Pool
如果要启动大量的子进程,可以用进程池的方式批量创建子进程:
from multiprocessing import Pool
import os, time, random
def long_time_task(name):
print('Run task %s (%s)...' % (name, os.getpid()))
start = time.time()
time.sleep(random.random() * 3)
end = time.time()
print('Task %s runs %0.2f seconds.' % (name, (end - start)))
if __name__=='__main__':
print('Parent process %s.' % os.getpid())
p = Pool(4)
for i in range(5):
p.apply_async(long_time_task, args=(i,))
print('Waiting for all subprocesses done...')
p.close()
p.join()
print('All subprocesses done.')对Pool对象调用join()方法会等待所有子进程执行完毕,调用join()之前必须先调用close(),调用close()之后就不能继续添加新的Process了。
子进程 subprocess()
很多时候,子进程并不是自身,而是一个外部进程。我们创建了子进程后,还需要控制子进程的输入和输出。
subprocess模块可以让我们非常方便地启动一个子进程,然后控制其输入和输出。
下面的例子演示了如何在Python代码中运行命令nslookup www.python.org,这和命令行直接运行的效果是一样的:
import subprocess
print('$ nslookup www.python.org')
r = subprocess.call(['nslookup', 'www.python.org'])
print('Exit code:', r)进程间通信
Process之间肯定是需要通信的,操作系统提供了很多机制来实现进程间的通信。Python的multiprocessing模块包装了底层的机制,提供了Queue、Pipes等多种方式来交换数据。
我们以Queue为例,在父进程中创建两个子进程,一个往Queue里写数据,一个从Queue里读数据:
from multiprocessing import Process, Queue
import os, time, random
# 写数据进程执行的代码:
def write(q):
print('Process to write: %s' % os.getpid())
for value in ['A', 'B', 'C']:
print('Put %s to queue...' % value)
q.put(value)
time.sleep(random.random())
# 读数据进程执行的代码:
def read(q):
print('Process to read: %s' % os.getpid())
while True:
value = q.get(True)
print('Get %s from queue.' % value)
if __name__=='__main__':
# 父进程创建Queue,并传给各个子进程:
q = Queue()
pw = Process(target=write, args=(q,))
pr = Process(target=read, args=(q,))
# 启动子进程pw,写入:
pw.start()
# 启动子进程pr,读取:
pr.start()
# 等待pw结束:
pw.join()
# pr进程里是死循环,无法等待其结束,只能强行终止:
pr.terminate()
3.2 多线程
多任务可以由多进程完成,也可以由一个进程内的多线程完成。
我们前面提到了进程是由若干线程组成的,一个进程至少有一个线程。
由于线程是操作系统直接支持的执行单元,因此,高级语言通常都内置多线程的支持,Python也不例外,并且,Python的线程是真正的Posix Thread,而不是模拟出来的线程。
Python的标准库提供了两个模块:_thread和threading,_thread是低级模块,threading是高级模块,对_thread进行了封装。绝大多数情况下,我们只需要使用threading这个高级模块。
启动一个线程就是把一个函数传入并创建Thread实例,然后调用start()开始执行:
import time, threading
# 新线程执行的代码:
def loop():
print('thread %s is running...' % threading.current_thread().name)
n = 0
while n < 5:
n = n + 1
print('thread %s >>> %s' % (threading.current_thread().name, n))
time.sleep(1)
print('thread %s ended.' % threading.current_thread().name)
print('thread %s is running...' % threading.current_thread().name)
t = threading.Thread(target=loop, name='LoopThread')
t.start()
t.join()
print('thread %s ended.' % threading.current_thread().name)
由于任何进程默认就会启动一个线程,我们把该线程称为主线程,主线程又可以启动新的线程,Python的threading模块有个current_thread()函数,它永远返回当前线程的实例。主线程实例的名字叫MainThread,子线程的名字在创建时指定,我们用LoopThread命名子线程。名字仅仅在打印时用来显示,完全没有其他意义,如果不起名字Python就自动给线程命名为Thread-1,Thread-2……
Lock
多线程和多进程最大的不同在于,多进程中,同一个变量,各自有一份拷贝存在于每个进程中,互不影响,而多线程中,所有变量都由所有线程共享,所以,任何一个变量都可以被任何一个线程修改,因此,线程之间共享数据最大的危险在于多个线程同时改一个变量,把内容给改乱了。
创建一个锁就是通过threading.Lock()来实现:
balance = 0
lock = threading.Lock()
def run_thread(n):
for i in range(100000):
# 先要获取锁:
lock.acquire()
try:
# 放心地改吧:
change_it(n)
finally:
# 改完了一定要释放锁:
lock.release()当多个线程同时执行lock.acquire()时,只有一个线程能成功地获取锁,然后继续执行代码,其他线程就继续等待直到获得锁为止。
获得锁的线程用完后一定要释放锁,否则那些苦苦等待锁的线程将永远等待下去,成为死线程。所以我们用try...finally来确保锁一定会被释放。
因为Python的线程虽然是真正的线程,但解释器执行代码时,有一个GIL锁:Global Interpreter Lock,任何Python线程执行前,必须先获得GIL锁,然后,每执行100条字节码,解释器就自动释放GIL锁,让别的线程有机会执行。这个GIL全局锁实际上把所有线程的执行代码都给上了锁,所以,多线程在Python中只能交替执行,即使100个线程跑在100核CPU上,也只能用到1个核。
GIL是Python解释器设计的历史遗留问题,通常我们用的解释器是官方实现的CPython,要真正利用多核,除非重写一个不带GIL的解释器。
所以,在Python中,可以使用多线程,但不要指望能有效利用多核。如果一定要通过多线程利用多核,那只能通过C扩展来实现,不过这样就失去了Python简单易用的特点。
不过,也不用过于担心,Python虽然不能利用多线程实现多核任务,但可以通过多进程实现多核任务。多个Python进程有各自独立的GIL锁,互不影响。
4、Python异步编程
我们知道,CPU的速度远远快于磁盘、网络等IO。在一个线程中,CPU执行代码的速度极快,然而,一旦遇到IO操作,如读写文件、发送网络数据时,就需要等待IO操作完成,才能继续进行下一步操作。这种情况称为同步IO。
在IO操作的过程中,当前线程被挂起,而其他需要CPU执行的代码就无法被当前线程执行了。
因为一个IO操作就阻塞了当前线程,导致其他代码无法执行,所以我们必须使用多线程或者多进程来并发执行代码,为多个用户服务。每个用户都会分配一个线程,如果遇到IO导致线程被挂起,其他用户的线程不受影响。
多线程和多进程的模型虽然解决了并发问题,但是系统不能无上限地增加线程。由于系统切换线程的开销也很大,所以,一旦线程数量过多,CPU的时间就花在线程切换上了,真正运行代码的时间就少了,结果导致性能严重下降。
由于我们要解决的问题是CPU高速执行能力和IO设备的龟速严重不匹配,多线程和多进程只是解决这一问题的一种方法。
另一种解决IO问题的方法是异步IO。当代码需要执行一个耗时的IO操作时,它只发出IO指令,并不等待IO结果,然后就去执行其他代码了。一段时间后,当IO返回结果时,再通知CPU进行处理。
可以想象如果按普通顺序写出的代码实际上是没法完成异步IO的:
do_some_code()
f = open('/path/to/file', 'r')
r = f.read() # <== 线程停在此处等待IO操作结果
# IO操作完成后线程才能继续执行:
do_some_code(r)所以,同步IO模型的代码是无法实现异步IO模型的。
异步IO模型需要一个消息循环,在消息循环中,主线程不断地重复“读取消息-处理消息”这一过程:
loop = get_event_loop()
while True:
event = loop.get_event()
process_event(event)消息模型其实早在应用在桌面应用程序中了。一个GUI程序的主线程就负责不停地读取消息并处理消息。所有的键盘、鼠标等消息都被发送到GUI程序的消息队列中,然后由GUI程序的主线程处理。
由于GUI线程处理键盘、鼠标等消息的速度非常快,所以用户感觉不到延迟。某些时候,GUI线程在一个消息处理的过程中遇到问题导致一次消息处理时间过长,此时,用户会感觉到整个GUI程序停止响应了,敲键盘、点鼠标都没有反应。这种情况说明在消息模型中,处理一个消息必须非常迅速,否则,主线程将无法及时处理消息队列中的其他消息,导致程序看上去停止响应。
消息模型是如何解决同步IO必须等待IO操作这一问题的呢?当遇到IO操作时,代码只负责发出IO请求,不等待IO结果,然后直接结束本轮消息处理,进入下一轮消息处理过程。当IO操作完成后,将收到一条“IO完成”的消息,处理该消息时就可以直接获取IO操作结果。
在“发出IO请求”到收到“IO完成”的这段时间里,同步IO模型下,主线程只能挂起,但异步IO模型下,主线程并没有休息,而是在消息循环中继续处理其他消息。这样,在异步IO模型下,一个线程就可以同时处理多个IO请求,并且没有切换线程的操作。对于大多数IO密集型的应用程序,使用异步IO将大大提升系统的多任务处理能力。
使用asyncio
使用asyncio - Python教程 - 廖雪峰的官方网站
asyncio是Python 3.4版本引入的标准库,直接内置了对异步IO的支持。
asyncio的编程模型就是一个消息循环。asyncio模块内部实现了EventLoop,把需要执行的协程扔到EventLoop中执行,就实现了异步IO。
用asyncio提供的@asyncio.coroutine可以把一个generator标记为coroutine类型,然后在coroutine内部用yield from调用另一个coroutine实现异步操作。
为了简化并更好地标识异步IO,从Python 3.5开始引入了新的语法async和await,可以让coroutine的代码更简洁易读。
用asyncio实现Hello world代码如下:
import asyncio
async def hello():
print("Hello world!")
# 异步调用asyncio.sleep(1):
await asyncio.sleep(1)
print("Hello again!")
asyncio.run(hello())async把一个函数变成coroutine类型,然后,我们就把这个async函数扔到asyncio.run()中执行。执行结果如下:
Hello!
(等待约1秒)
Hello again!hello()会首先打印出Hello world!,然后,await语法可以让我们方便地调用另一个async函数。由于asyncio.sleep()也是一个async函数,所以线程不会等待asyncio.sleep(),而是直接中断并执行下一个消息循环。当asyncio.sleep()返回时,就接着执行下一行语句。
把asyncio.sleep(1)看成是一个耗时1秒的IO操作,在此期间,主线程并未等待,而是去执行EventLoop中其他可以执行的async函数了,因此可以实现并发执行。
上述hello()还没有看出并发执行的特点,我们改写一下,让两个hello()同时并发执行:
# 传入name参数:
async def hello(name):
# 打印name和当前线程:
print("Hello %s! (%s)" % (name, threading.current_thread))
# 异步调用asyncio.sleep(1):
await asyncio.sleep(1)
print("Hello %s again! (%s)" % (name, threading.current_thread))
return name用asyncio.gather()同时调度多个async函数:
async def main():
L = await asyncio.gather(hello("Bob"), hello("Alice"))
print(L)
asyncio.run(main())Hello Bob! (<function current_thread at 0x10387d260>)
Hello Alice! (<function current_thread at 0x10387d260>)
(等待约1秒)
Hello Bob again! (<function current_thread at 0x10387d260>)
Hello Alice again! (<function current_thread at 0x10387d260>)
['Bob', 'Alice']5、uvicorn服务器
(14 封私信 / 80 条消息) uvicorn,一个无敌的 Python 库! - 知乎
1