RAG各个环节的原理
早期(Naive RAG)RAG在实操时,会出现各种各样的问题。如准确率低,可能出现幻觉,召回率低,导致信息不完整,过时或者冗余的信息导致检索结果不准确。
幻觉:答非所问,生成有害或有偏见的答案
增强过程中,内容不连贯,冗余或重复,生成结果可能过度依赖增强信息,导致和增强信息相比没有带来额外的收益(LLM的强大功能没有使用上。)
现在的RAG(Advanced RAG)在早期rag的基础上进行了改进,充分利用各个环节的优势,提高效率和质量。
检索前:增强数据粒度:修订和简化数据内容,确保正确性和可读性,删除不相关的信息和歧义,如使用Pypdf进行pdf处理,中文分词时使用jieba库或word2vec库进行分词,维护上下文连贯性。
优化索引结构:调整chunk大小以捕捉相关上下文,简历知识图谱(graph结构)
对于复杂问题,如果只使用rag会造成不准确,所以要配合agent来解决。如下图:
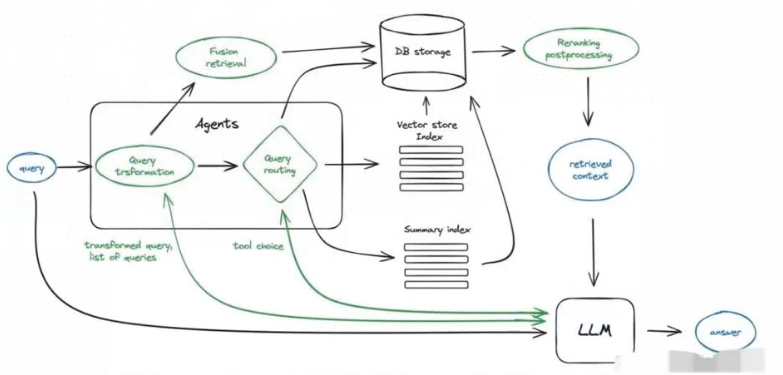
该图中,首先将问题(query)过一次LLM,用LLM将用户的复杂问题拆解成多个简单的小问题,然后由agents区解决这些问题,如从数据库中查找,从网上查找等,将查找到的数据进行reank,然后多路找回,再结合LLM生成答案。
一、RAG与微调
什么时候用微调:
模型定制,比如要求模型有特定知识,以某种口吻回复问题,需要在特定数据集上进行训练模型
智能设备:边缘设备,如智能眼镜,车载设备等,要求响应快,精度高,可以对模型进行蒸馏剪枝和量化,再在特定数据集上微调
什么时候用RAG:
可解释性高:知识都是从知识库中查找的,有依据可查
成本低:微调需要的时间长,还需要有特定数据集
少幻觉
1