langchain-ai/langchain: 🦜🔗 Build context-aware reasoning applications
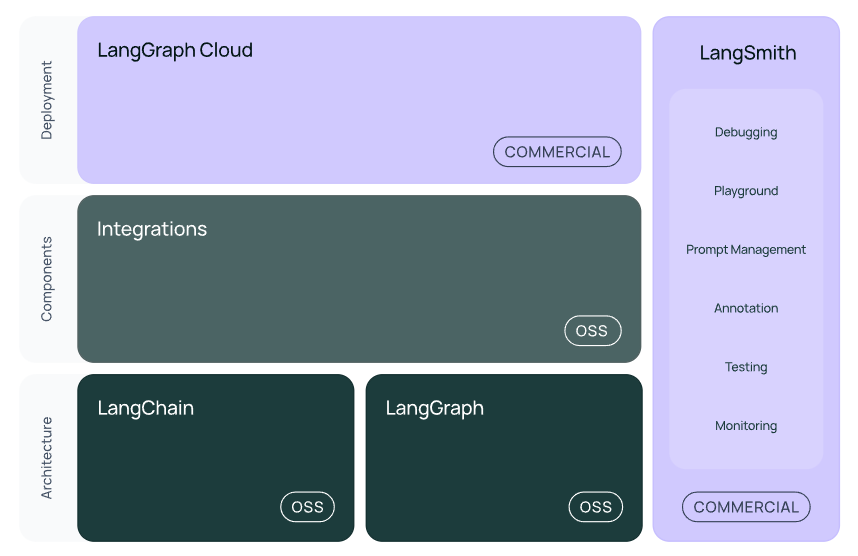
LangChain:Model I/O, Chain, Agent,组成应用程序认知架构的链、代理和检索策略
LangGraph:将多个Chain,agent构建成图结构,能够处理更加复杂的问题
LangSimth:评估,监控,从开发到生成的过渡
LangGraph Cloud: 将的 LangGraph 应用程序转变为生产就绪的 API 和助手,供前端或其他调用
LangServe:部署应用
LangChain可以从六个方面进行学习,即Model I/O, Retrieval, Chains, Memory, Agents, Callbacks.
一、Model I/O
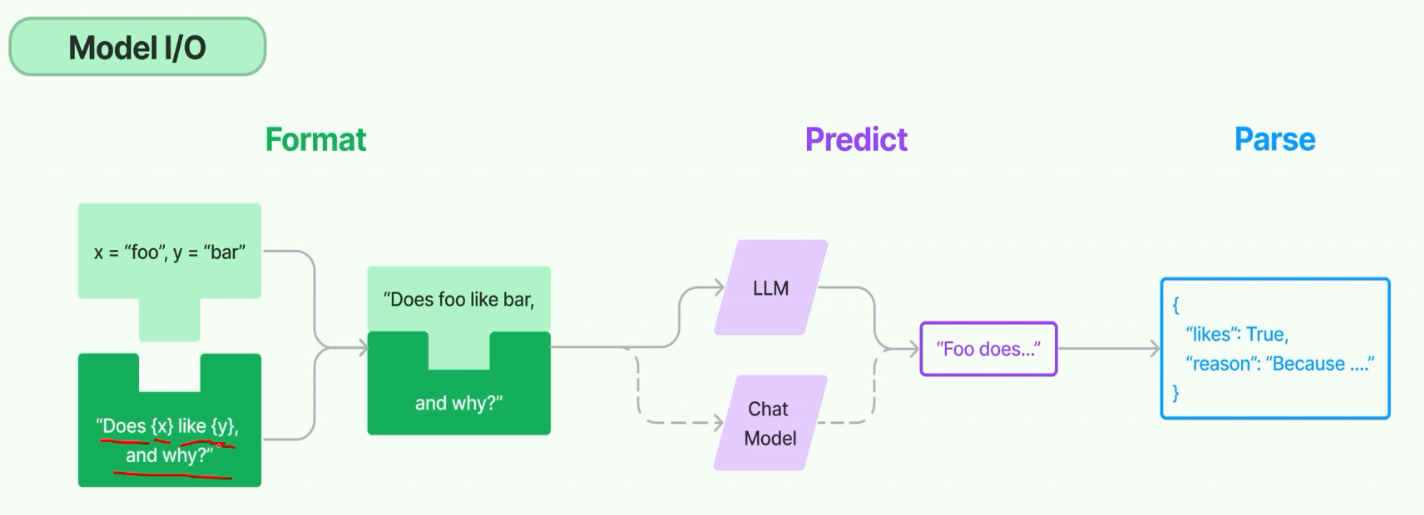
在 LangChain 中,Model I/O(模型输入输出) 是连接用户与大语言模型(LLM)的核心模块,负责 处理输入(将用户需求转换为模型可理解的格式)、调用模型(与 LLM 交互)、处理输出(将模型返回结果转换为用户友好的形式) 三大核心任务。它是 LangChain 中所有涉及 LLM 调用场景(如 Chain、Agent、RAG)的基础,确保模型与用户、其他组件(如 Memory、Tools)之间的顺畅协作。
一、Model I/O 的核心价值与流程
Model I/O 的本质是 “模型交互的中间层”,解决了以下关键问题:
输入标准化:将用户的自然语言、结构化数据(如对话历史)转换为符合 LLM 要求的 Prompt 格式;
模型适配:统一不同 LLM 的调用接口(如 OpenAI、本地模型、Anthropic),屏蔽底层 API 差异;
输出解析:将 LLM 生成的原始文本转换为结构化数据(如 JSON、列表),便于后续处理(如工具调用、结果展示)。
其核心流程可概括为:
plaintext
用户输入 → [输入处理(Prompt 构建)] → [模型调用(LLM 推理)] → [输出处理(结果解析)] → 用户/下游组件二、Model I/O 的核心组件
LangChain 的 Model I/O 模块包含三个核心组件,分别对应上述流程的三个阶段:
三、核心组件详解与实战
1. Prompts:构建模型输入
Prompts 的核心是 “模板化”—— 通过预定义模板,动态插入变量(如用户输入、上下文),生成符合 LLM 预期的输入文本。
(1)基础模板:PromptTemplate
适用于非对话式 LLM(如文本生成模型),支持简单变量替换。
from langchain.prompts import PromptTemplate
# 定义模板(用 {变量名} 标记占位符)
template = "请用一句话总结以下内容:{text}"
# 创建 PromptTemplate 实例
prompt = PromptTemplate(
input_variables=["text"], # 声明变量名
template=template
)
# 填充变量,生成最终 Prompt
user_text = "LangChain 是一个用于构建 LLM 应用的框架,它提供了 Model I/O、Memory、Agent 等模块。"
final_prompt = prompt.format(text=user_text)
print("最终输入到 LLM 的文本:")
print(final_prompt)(2)对话模板:ChatPromptTemplate
适用于对话式模型(如 GPT-4、DeepSeek),支持区分 “系统提示”“用户输入”“AI 回复” 等角色,更符合聊天模型的交互逻辑。
from langchain.prompts import ChatPromptTemplate
from langchain.schema import HumanMessage, SystemMessage, AIMessage
# 定义对话模板(按角色区分消息)
chat_template = ChatPromptTemplate.from_messages([
("system", "你是一个专业的技术助手,回答需简洁准确。"), # 系统提示(定义 AI 角色)
("human", "什么是 {concept}?"), # 用户输入(带变量 {concept})
("ai", "我之前解释过 {related_concept},它是 {concept} 的相关技术。"), # 历史 AI 回复(可选)
])
# 填充变量,生成对话消息列表
messages = chat_template.format_messages(
concept="Model I/O",
related_concept="Prompt 工程"
)
# 打印生成的消息(每个消息包含角色和内容)
for msg in messages:
print(f"{msg.type}: {msg.content}")2. Language Models:调用 LLM
LangChain 封装了多种 LLM 类型,提供统一的调用接口(predict/generate 方法),无需关心底层模型的 API 差异。
(1)调用聊天模型(ChatModel)
适用于对话式模型(如 GPT-4、DeepSeek),输入为消息列表(SystemMessage/HumanMessage 等),输出为 AIMessage。
from langchain_huggingface import HuggingFacePipeline
from transformers import AutoTokenizer, AutoModelForCausalLM, pipeline
from langchain.schema import HumanMessage
# 初始化本地聊天模型(以 DeepSeek-7B 为例)
def init_chat_model():
model_name = "deepseek-ai/deepseek-llm-7b-chat"
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
model_name, trust_remote_code=True, device_map="auto", load_in_4bit=True
)
# 构建文本生成管道
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
max_new_tokens=200,
temperature=0.3
)
return HuggingFacePipeline(pipeline=pipe)
# 初始化模型
chat_model = init_chat_model()
# 调用模型(输入为消息列表)
messages = [
HumanMessage(content="用3句话解释 LangChain 的 Model I/O 模块")
]
response = chat_model.invoke(messages) # 同步调用
print("模型输出:", response.content)(2)调用文本生成模型(LLM)
适用于非对话式模型(如 GPT-3、Llama 2),输入为纯文本,输出为生成的文本。
from langchain_community.llms import Ollama # 以 Ollama 部署的 Llama 2 为例
# 初始化 LLM(通过 Ollama 调用本地 Llama 2)
llm = Ollama(model="llama2", temperature=0.3)
# 调用模型(输入为纯文本)
prompt = "总结 LangChain 中 Model I/O 的作用"
response = llm.invoke(prompt) # 同步调用
print("模型输出:", response)3. Output Parsers:解析模型输出
LLM 生成的原始文本通常是无结构的字符串,Output Parsers 可将其转换为结构化数据(如 JSON、列表、Pydantic 模型),便于后续处理(如提取关键信息、调用工具)。
(1)JsonOutputParser:解析为 JSON
from langchain.output_parsers import JsonOutputParser
from langchain.prompts import PromptTemplate
from langchain_huggingface import HuggingFacePipeline
# 初始化模型(复用之前的 chat_model)
chat_model = init_chat_model()
# 定义输出格式(JSON 结构)
parser = JsonOutputParser()
# 获取格式说明(用于提示 LLM 按指定格式输出)
format_instructions = parser.get_format_instructions()
# 定义 Prompt 模板(包含格式说明)
prompt = PromptTemplate(
template="请解析以下内容为 JSON,包含 'name' 和 'category' 字段。\n{format_instructions}\n内容:{text}",
input_variables=["text"],
partial_variables={"format_instructions": format_instructions} # 注入格式说明
)
# 生成 Prompt 并调用模型
text = "苹果是一种常见的水果,味道甜美。"
final_prompt = prompt.format(text=text)
response = chat_model.invoke([HumanMessage(content=final_prompt)])
# 解析输出为 JSON
parsed_output = parser.parse(response.content)
print("解析后的 JSON:", parsed_output)
print("提取的类别:", parsed_output["category"]) # 访问 JSON 字段(2)PydanticOutputParser:解析为 Pydantic 模型
更灵活的结构化解析,支持字段验证(如类型、约束),适合复杂场景。
from langchain.output_parsers import PydanticOutputParser
from pydantic import BaseModel, Field
from typing import List
# 定义 Pydantic 模型(结构化输出格式)
class Product(BaseModel):
name: str = Field(description="产品名称")
price: float = Field(description="产品价格(数字)")
tags: List[str] = Field(description="产品标签列表")
# 初始化解析器
parser = PydanticOutputParser(pydantic_object=Product)
format_instructions = parser.get_format_instructions()
# 定义 Prompt 模板
prompt = PromptTemplate(
template="请解析以下产品信息为指定格式。\n{format_instructions}\n信息:{info}",
input_variables=["info"],
partial_variables={"format_instructions": format_instructions}
)
# 生成 Prompt 并调用模型
product_info = "产品名称:智能手表,价格:1299元,标签:电子设备、可穿戴、健康监测"
final_prompt = prompt.format(info=product_info)
response = chat_model.invoke([HumanMessage(content=final_prompt)])
# 解析为 Product 对象
product = parser.parse(response.content)
print("解析后的产品对象:", product)
print("产品价格:", product.price) # 直接访问对象字段(自动转换为 float 类型)四、Model I/O 与其他模块的协作(见下文)
Model I/O 是 LangChain 的 “核心枢纽”,与其他模块(Memory、Retrieval、Agent)紧密协作:
与 Memory 协作:
Prompts结合Memory中的对话历史,生成包含上下文的 Prompt(如多轮对话中,将历史消息插入ChatPromptTemplate);与 Retrieval 协作:
Prompts将检索到的文档(Document)作为 “上下文” 插入模板,让 LLM 基于外部知识生成回答(RAG 流程);与 Agent 协作:
Output Parsers将 LLM 生成的工具调用指令(如{"action": "tool_name", "parameters": {...}})解析为结构化数据,指导 Agent 执行工具调用。
五、最佳实践
Prompt 工程优化:
明确任务要求(如 “用 3 句话总结”“输出 JSON 格式”);
加入示例(少样本学习)提升模型输出质量;
控制 Prompt 长度,避免超出 LLM 上下文窗口。
模型选择适配:
对话场景用
ChatModel(如 GPT-4、DeepSeek),文本生成场景用LLM(如 Llama 2);本地部署优先选择轻量级模型(如 7B 参数模型),平衡性能与效率。
输出解析容错:
模型可能生成不符合格式的输出,需用
try-except捕获解析错误,并在 Prompt 中强化格式要求;复杂结构优先用
PydanticOutputParser,利用其字段验证功能过滤无效数据。
二、Retrieval
在 LangChain 中,Retrieval(检索) 是实现 RAG(Retrieval-Augmented Generation,检索增强生成) 的核心模块,其核心作用是 从外部知识库(如文档、数据库、API)中精准提取与用户查询相关的信息,并将这些信息作为上下文传递给 LLM,让 LLM 基于 “外部知识” 生成更准确、更具时效性的回答(而非仅依赖 LLM 训练时的内置知识)。
一、Retrieval 的核心价值与应用场景
Retrieval 解决了 LLM 的两大核心痛点:
知识时效性:LLM 训练数据有截止日期(如 GPT-4 截止到 2023 年),无法回答最新信息(如 2024 年新政策、新品发布);
知识局限性:LLM 无法掌握领域专属知识(如企业内部文档、学术论文、行业数据)。
通过 Retrieval,LangChain 可将 LLM 与任意外部知识库结合,典型应用场景包括:
企业内部文档问答(如员工手册、产品手册查询);
学术论文 / 技术文档解析(如根据论文内容回答研究问题);
实时信息问答(如结合搜索引擎 API 回答最新新闻、天气);
多源数据整合(如从 CSV 表格、SQL 数据库中检索数据并生成分析报告)。
二、Retrieval 的核心组件与工作流程
LangChain 的 Retrieval 模块围绕 “从知识库中高效检索相关信息” 设计,核心组件包括 Retriever(检索器)、Vector Store(向量存储) 和 Document Loader(文档加载器),完整工作流程如下:
1. 核心组件
2. 完整工作流程(RAG 流程)
Retrieval 是 RAG 的 “检索阶段”,与 “生成阶段”(LLM 生成回答)共同构成完整 RAG 流程,分为 离线准备 和 在线问答 两步:
步骤 1:离线准备(知识库构建)
加载文档:用
Document Loader将外部数据(如 PDF、TXT)加载为Document对象;文本分块:用
Text Splitter将长Document拆分为短文本块(如每块 500 字符,重叠 50 字符);生成向量:用
Embedding模型将每个文本块转换为向量;存储向量:将向量和对应文本块存入
Vector Store,形成可检索的知识库。
步骤 2:在线问答(检索 + 生成)
用户查询:用户输入问题(如 “产品 A 的保修期是多久?”);
检索相关文本:用
Retriever将用户查询转换为向量,在Vector Store中查询最相似的 N 个文本块(如 Top 3);构建 Prompt:将检索到的文本块作为 “上下文”,与用户查询拼接成 Prompt(如 “根据上下文回答:{context}\n 问题:{query}”);
LLM 生成回答:将 Prompt 传入 LLM,生成基于外部知识库的回答。
具体代码可以参考:RAG应用实践 | 禧语许
https://github.com/XuWink/SimpleRAG.git
三、Chains
设计理念:通过很多小的chain构成Chains,形成一个可行的项目
3.1 基于LCEC的
LangChain 表达式语言 (LCEL) |🦜️🔗 朗链
LangChain Expression Language(LCEL)通过 RunnableSequence(顺序执行) 和 RunnableParallel(并行执行) 实现这种“调用链”。
在 LangChain 中,每个步骤都是一个 Runnable 对象,包括:
模型(LLM)
Prompt 模板
外部函数或工具(Tool)
输出解析器(Parser)
这些 Runnables 可以通过两种方式组合:
RunnableSequence:顺序执行(pipeline)RunnableParallel:并行执行(map)
使用
RunnableSequence
from langchain_core.runnables import RunnableSequence
chain = RunnableSequence([runnable1, runnable2])
final_output = chain.invoke(some_input)
# 等价于下面的过程
output1 = runnable1.invoke(some_input)
final_output = runnable2.invoke(output1)使用
RunnableParallel
from langchain_core.runnables import RunnableParallel
chain = RunnableParallel({
"key1": runnable1,
"key2": runnable2,
})
# 例如
from langchain_core.runnables import RunnableParallel
cities = ["杭州", "北京", "上海"]
parallel_chain = RunnableParallel(
**{city: RunnableLambda(lambda _: get_weather(city)) for city in cities}
)
weather_results = parallel_chain.invoke(None)
print(weather_results) # {'杭州': '晴,气温 26°C', '北京': '多云,气温 20°C', '上海': '小雨,气温 22°C'}
使用
|pipe运算符
chain = runnable1 | runnable2
# 等价于:
chain = RunnableSequence([runnable1, runnable2])
# 或:
chain = runnable1.pipe(runnable2)LCEL 应用自动类型强制,使链的组成更容易
mapping = {
"key1": runnable1,
"key2": runnable2,
}
chain = mapping | runnable3会自动转换成:
chain = RunnableSequence([RunnableParallel(mapping), runnable3])在 LCEL 表达式中,函数会自动转换为 .
RunnableLambda
def some_func(x):
return x
chain = some_func | runnable1
# 自动转换为:
chain = RunnableSequence([RunnableLambda(some_func), runnable1])routerchain
(10 封私信 / 80 条消息) Langchain Chain - RouterChain 根据输入相关性进行路由的路由链 - 知乎
根据用户的数据,自动选择下游多个链中对应的一个。
1. 创建子链和默认链
2. 创建路由链,同时路由链的路由模板需要根据子链进行特殊设计
3. 创建MultiPromptChain,将路由链、默认链和子链组装成一个整体
from langchain.chains.router.llm_router import RouterOutputParser
from langchain.chains.router.llm_router import LLMRouterChain
from langchain.llms import OpenAI
import os
router_prompt = PromptTemplate(
template=router_template,
input_variables=["input"],
output_parser=RouterOutputParser(),
)
#创建一个OpenAI作为大语言模型的基底
llm = OpenAI()
os.environ["OPENAI_API_KEY"]="你的key"
# 创建路由链
router_chain = LLMRouterChain.from_llm(llm, router_prompt)
# 生成目标链
candadite_chains = {}
# 遍历路由目录,生成各子链并放入候选链字典
for p_info in prompt_infos:
name = p_info["name"]
prompt_template = p_info["prompt_template"]
prompt = PromptTemplate(template=prompt_template, input_variables=["input"])
chain = LLMChain(llm=llm, prompt=prompt)
candadite_chains[name] = chain
# 生成默认链
default_chain = ConversationChain(llm=llm, output_key="text")
# MultiPromptChain所必须的三大要素:router_chain, destination_chain 以及 default_chain
chain = MultiPromptChain(
router_chain=router_chain,
destination_chains=candadite_chains,
default_chain=default_chain,
verbose=True,
)
print(chain.run("帮我写一首关于春天的诗"))四、Memory
玩转 LangChain Memory 模块:四种记忆类型详解及应用场景全覆盖-CSDN博客
在 LangChain 中,Memory(记忆) 是实现对话连贯性、上下文感知的核心组件,其核心作用是 存储和管理对话历史 / 上下文信息,让 LLM(大语言模型)能基于历史交互生成更连贯、更贴合场景的回复。
LangChain 提供了丰富的 Memory 实现,覆盖不同场景(如单轮 / 多轮对话、结构化 / 非结构化记忆、持久化存储等),且支持与 Chain(链)、Agent(智能体)无缝集成。
根据存储内容、生命周期和使用场景,Memory 可分为以下几类:
LangChain 中最常用的是 对话类 Memory,以下介绍高频使用的实现及代码示例(基于 LangChain v0.2+ 版本)
1. 基础款:ConversationBufferMemory(全量存储对话历史)
原理:以纯文本形式全量存储所有对话历史(用户输入 + AI 回复),生成回复时将完整历史传入 LLM。
优点:简单直观,适合短对话;
缺点:对话过长时会导致 LLM 输入超限(Context Window 不足),且效率低
from langchain_community.chat_models import ChatOpenAI # 也可替换为本地LLM(如DeepSeek)
from langchain.chains import ConversationChain
from langchain.memory import ConversationBufferMemory
# 1. 初始化LLM(以OpenAI为例,本地LLM需替换为HuggingFacePipeline等)
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0.3)
# 2. 初始化Memory:存储全量对话历史,可指定输出格式(如"human"和"ai"的键名)
memory = ConversationBufferMemory(
memory_key="history", # 对话历史在Prompt中的变量名
return_messages=True # 若为True,返回Message对象;False返回纯文本字符串
)
# 3. 初始化对话链(将LLM与Memory绑定)
conversation_chain = ConversationChain(
llm=llm,
memory=memory,
verbose=True # 开启 verbose,可查看完整Prompt(含对话历史)
)
# 4. 多轮对话交互
response1 = conversation_chain.predict(input="介绍一下LangChain的Memory组件")
print("AI回复1:", response1)
# 第二轮对话:依赖上一轮的上下文
response2 = conversation_chain.predict(input="它有哪些常见的实现方式?")
print("AI回复2:", response2)
# 查看当前存储的对话历史
print("\n当前对话历史:")
print(memory.load_memory_variables({})) # load_memory_variables() 读取记忆2. 优化款:ConversationBufferWindowMemory(滑动窗口记忆)
原理:只存储最近 N 轮对话历史(类似 “滑动窗口”),避免历史过长导致 LLM 输入超限。
核心参数:
k—— 保留的对话轮数(如k=3表示只保留最近 3 轮)。适用场景:中等长度对话,平衡上下文完整性和输入长度。
from langchain.memory import ConversationBufferWindowMemory
# 初始化滑动窗口Memory:只保留最近2轮对话
memory = ConversationBufferWindowMemory(
memory_key="history",
return_messages=True,
k=2 # 关键参数:保留2轮对话(1轮=用户输入+AI回复)
)
# 绑定到对话链
conversation_chain = ConversationChain(llm=llm, memory=memory, verbose=True)
# 多轮对话
conversation_chain.predict(input="第一轮:什么是LangChain?")
conversation_chain.predict(input="第二轮:它的核心模块有哪些?")
conversation_chain.predict(input="第三轮:Memory模块属于核心模块吗?")
# 查看记忆:只保留第2、3轮对话(k=2)
print("\n滑动窗口记忆内容:")
print(memory.load_memory_variables({}))3. 高效款:ConversationSummaryMemory(对话摘要记忆)
原理:不存储全量历史,而是对早期对话生成 “摘要”,仅保留摘要 + 最近几轮对话,大幅减少输入长度。
优点:适合长对话,兼顾上下文连贯性和效率;
注意:需要额外调用 LLM 生成摘要(会增加少量 token 消耗)。
from langchain.memory import ConversationSummaryMemory
# 初始化摘要Memory:需传入LLM(用于生成对话摘要)
memory = ConversationSummaryMemory(
memory_key="history",
return_messages=True,
llm=llm # 用于生成摘要的LLM(建议与对话LLM一致)
)
# 长对话测试
conversation_chain = ConversationChain(llm=llm, memory=memory, verbose=True)
# 多轮对话(早期对话会被总结)
conversation_chain.predict(input="LangChain是一个用于构建LLM应用的框架,它提供了很多组件。")
conversation_chain.predict(input="其中Memory组件负责存储对话历史,让LLM能记住上下文。")
conversation_chain.predict(input="除了Memory,还有Chain、Agent、DocumentLoader等组件。")
conversation_chain.predict(input="刚才提到的Memory组件,有哪些优化存储的实现?")
# 查看记忆:早期对话已被总结,最近对话保留原文
print("\n摘要记忆内容:")
print(memory.load_memory_variables({}))4. 结构化款:ConversationEntityMemory(实体记忆)
原理:不仅存储对话历史,还会提取对话中的 “实体”(如人名、产品名、属性),以 Key-Value 形式结构化存储(如 “产品 A:价格 100 元,产地北京”)。
适用场景:需要精准跟踪实体属性的场景(如电商客服、CRM 对话)。
from langchain.memory import ConversationEntityMemory
from langchain.memory.prompt import ENTITY_MEMORY_CONVERSATION_TEMPLATE
# 初始化实体Memory
memory = ConversationEntityMemory(
llm=llm,
memory_key="history",
return_messages=True
)
# 绑定对话链(使用实体记忆专用的Prompt模板)
conversation_chain = ConversationChain(
llm=llm,
memory=memory,
prompt=ENTITY_MEMORY_CONVERSATION_TEMPLATE, # 关键:使用实体模板
verbose=True
)
# 对话中包含实体属性
conversation_chain.predict(input="我想买产品A,它的价格是多少?")
conversation_chain.predict(input="产品A的保修期有多久?")
conversation_chain.predict(input="那产品B呢?价格比A贵吗?")
# 查看提取的实体(结构化存储)
print("\n提取的实体信息:")
print(memory.entity_store.store) # entity_store.store 存储实体的Key-Value5. RAG + Memory(带记忆的检索问答)
在 RAG(检索增强生成)中加入 Memory,让系统能记住 “用户之前问过的问题”“已检索过的文档”,避免重复检索或上下文断裂。
from langchain.chains import RetrievalQAWithSourcesChain
from langchain_community.vectorstores import Chroma
from langchain_huggingface import HuggingFaceEmbeddings
# 1. 初始化向量库(RAG基础)
embeddings = HuggingFaceEmbeddings(model_name="BAAI/bge-large-zh-v1.5")
vector_db = Chroma(persist_directory="chroma_vector_db", embedding_function=embeddings)
retriever = vector_db.as_retriever(top_k=3)
# 2. 初始化Memory(存储对话历史)
memory = ConversationBufferWindowMemory(
memory_key="history",
return_messages=True,
k=2 # 保留最近2轮对话
)
# 3. 初始化带记忆的RAG链
rag_chain = RetrievalQAWithSourcesChain.from_chain_type(
llm=llm,
chain_type="stuff", # 简单拼接上下文
retriever=retriever,
memory=memory,
verbose=True,
return_source_documents=True # 返回检索到的文档来源
)
# 4. 多轮RAG问答(基于记忆关联上下文)
response1 = rag_chain({"question": "文档中提到的产品A价格是多少?"})
print("回答1:", response1["answer"])
# 第二轮:依赖上一轮的“产品A”上下文
response2 = rag_chain({"question": "它的折扣活动持续到什么时候?"})
print("回答2:", response2["answer"])6. Agent + Memory(带记忆的智能体)
Agent 在执行任务时(如 “查询天气→规划出行路线”),需要 Memory 记录已完成的动作、获取的信息,避免重复操作。
from langchain.agents import create_structured_chat_agent
from langchain.agents import AgentExecutor
from langchain.tools import Tool
from langchain import hub
# 1. 定义工具(示例:模拟查询天气工具)
def get_weather(city: str) -> str:
"""查询指定城市的天气"""
return f"{city}今天天气晴朗,气温25℃。"
tools = [
Tool(
name="WeatherQuery",
func=get_weather,
description="用于查询城市天气,输入参数为城市名(如“北京”)"
)
]
# 2. 初始化Memory(记录Agent的动作和对话)
memory = ConversationBufferMemory(
memory_key="chat_history",
return_messages=True,
output_key="output" # 匹配Agent的输出键
)
# 3. 加载Agent模板(结构化对话模板)
prompt = hub.pull("hwchase17/structured-chat-agent")
# 4. 初始化带记忆的Agent
agent = create_structured_chat_agent(llm=llm, tools=tools, prompt=prompt)
agent_executor = AgentExecutor(
agent=agent,
tools=tools,
memory=memory,
verbose=True,
handle_parsing_errors=True
)
# 5. Agent执行任务(记忆会记录“查询过北京天气”)
agent_executor.invoke({"input": "查询北京的天气"})
agent_executor.invoke({"input": "那明天适合去公园吗?"}) # 依赖上一轮的“北京天气”上下文7. Memory 持久化(跨会话存储)
默认的 Memory 是临时存储(会话结束后内存清空),若需跨会话保留(如 “用户下次登录仍能获取历史对话”),需将 Memory 持久化到外部存储(如数据库、文件)。
LangChain 支持多种持久化方式,以下是 基于 SQLite 数据库 的示例:
from langchain.memory import ConversationBufferMemory
from langchain_community.utilities import SQLDatabase
from langchain.memory.chat_message_histories import SQLChatMessageHistory
# 1. 连接SQLite数据库(本地文件数据库)
db = SQLDatabase.from_uri("sqlite:///chat_history.db")
# 2. 初始化数据库存储的对话历史(需指定session_id,区分不同用户/会话)
chat_history = SQLChatMessageHistory(
session_id="user_123", # 每个用户/会话的唯一ID
connection_string="sqlite:///chat_history.db"
)
# 3. 初始化Memory,绑定数据库存储
memory = ConversationBufferMemory(
memory_key="history",
return_messages=True,
chat_memory=chat_history # 关键:使用数据库存储的对话历史
)
# 4. 对话链(跨会话后,memory会从数据库读取历史)
conversation_chain = ConversationChain(llm=llm, memory=memory, verbose=True)
# 对话(内容会自动存入SQLite)
conversation_chain.predict(input="我是用户123,今天咨询产品A的价格。")
# 下次启动程序时,只需传入相同的session_id,即可读取历史对话五、Agents
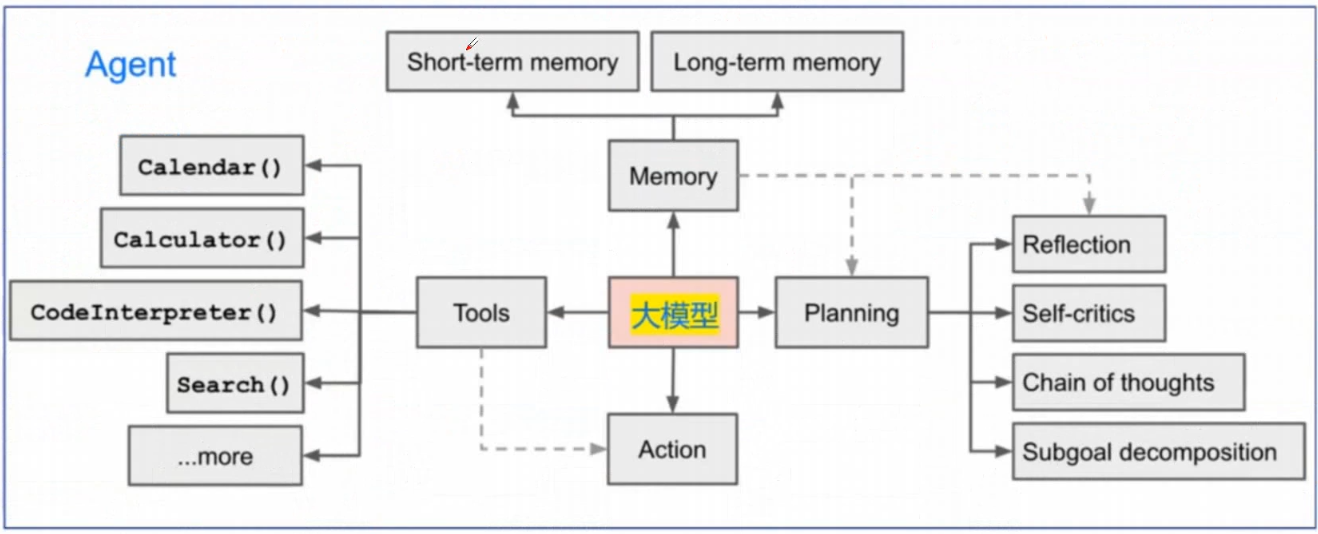
在 LangChain 中,Agent(智能体) 是一个能根据用户需求 自主规划、调用工具、处理复杂任务 的核心组件。与普通的 Chain(链)不同,Agent 具备 决策能力—— 它能分析问题、判断是否需要工具、选择合适工具、执行并反思结果,最终完成单轮链无法处理的复杂任务(例如 “查询北京明天天气,再推荐适合的景点”“根据最近股价分析某公司投资价值”)。
一、Agent 的核心原理与组成
1. 核心能力
目标拆解:将复杂任务分解为可执行的子步骤(例如 “规划旅行”→“查天气→订机票→推荐酒店”);
工具调用:根据子步骤选择合适工具(如搜索引擎、数据库、计算器等);
结果反思:评估工具返回的结果是否满足需求,若不满足则调整策略(如重新调用工具、补充信息);
自然语言交互:用自然语言接收输入、输出最终结果,无需用户掌握技术细节。
2. 核心组成部分
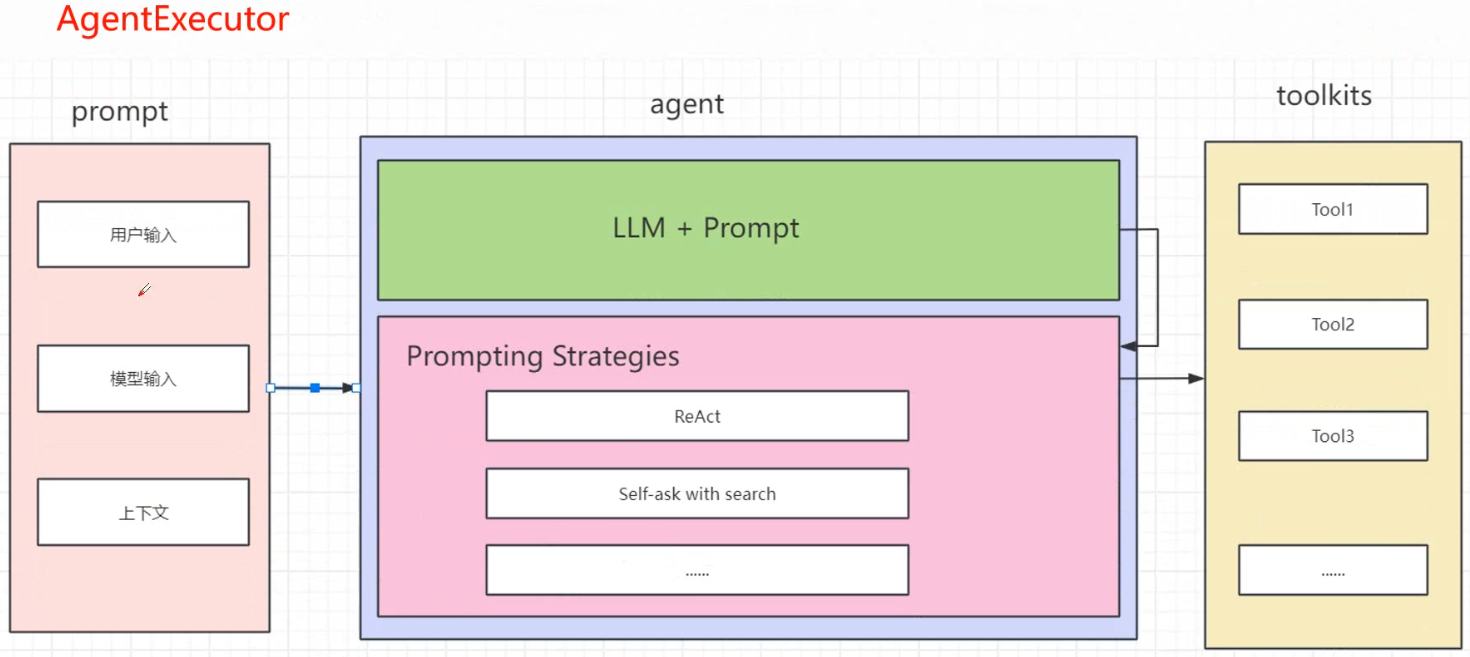
二、常见 Agent 类型及适用场景
LangChain 提供了多种 Agent 实现,核心差异在于 决策逻辑 和 工具调用方式,以下是最常用的 3 类:
from langchain.agents import create_structured_chat_agent, AgentExecutor
from langchain.tools import Tool
from langchain import hub
from langchain.memory import ConversationBufferMemory
from langchain_huggingface import HuggingFacePipeline
from transformers import AutoTokenizer, AutoModelForCausalLM, pipeline
# ========================== 1. 初始化 LLM(本地模型示例:DeepSeek-7B) ==========================
def init_llm():
model_name = "deepseek-ai/deepseek-llm-7b-chat"
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
model_name,
trust_remote_code=True,
device_map="auto",
load_in_4bit=True # 4bit量化,节省显存
)
# 构建文本生成管道
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
max_new_tokens=512,
temperature=0.3,
return_full_text=False
)
return HuggingFacePipeline(pipeline=pipe)
llm = init_llm()
# ========================== 2. 定义工具(Tools) ==========================
# 工具1:查询天气(模拟)
def get_weather(city: str, date: str) -> str:
"""
查询指定城市和日期的天气情况。
参数:
city: 城市名称(如“北京”“上海”)
date: 日期(如“2023-10-01”或“明天”)
返回:
天气描述字符串
"""
# 实际场景中可替换为真实天气API调用
return f"{city} {date}的天气为:晴朗,气温25℃,微风。"
# 工具2:计算器(支持简单数学运算)
def calculate(expression: str) -> str:
"""
计算数学表达式的结果(仅支持加减乘除和括号)。
参数:
expression: 数学表达式(如“1+2*3”“(5+8)/2”)
返回:
计算结果字符串
"""
try:
# 注意:实际使用需限制表达式安全性(避免代码注入)
result = eval(expression)
return f"计算结果:{expression} = {result}"
except Exception as e:
return f"计算错误:{str(e)}"
# 工具列表:将函数包装为 Tool 对象(name 是工具名,func 是函数,description 是工具描述)
tools = [
Tool(
name="WeatherQuery",
func=get_weather,
description="用于查询指定城市和日期的天气,需要传入city(城市名)和date(日期)两个参数。"
),
Tool(
name="Calculator",
func=calculate,
description="用于计算数学表达式,需要传入expression(如'1+2*3')参数。"
)
]
# ========================== 3. 初始化 Memory(对话记忆) ==========================
memory = ConversationBufferMemory(
memory_key="chat_history", # 记忆在Prompt中的变量名
return_messages=True, # 返回Message对象(而非纯文本)
output_key="output" # 与Agent输出键匹配,确保记忆正确存储
)
# ========================== 4. 加载 Agent 提示模板 ==========================
# 从 LangChain Hub 加载结构化对话Agent的默认模板(也可自定义)
prompt = hub.pull("hwchase17/structured-chat-agent")
# ========================== 5. 创建 Agent 和执行器 ==========================
# 创建结构化聊天Agent
agent = create_structured_chat_agent(
llm=llm,
tools=tools,
prompt=prompt
)
# 创建Agent执行器(包装Agent,负责运行和处理输出)
agent_executor = AgentExecutor(
agent=agent,
tools=tools,
memory=memory,
verbose=True, # 开启详细日志,查看Agent思考和工具调用过程
handle_parsing_errors=True # 自动处理工具调用格式错误
)
# ========================== 6. 测试 Agent ==========================
print("开始与Agent对话(输入'退出'结束):")
while True:
user_input = input("\n你:").strip()
if user_input.lower() in ["退出", "q"]:
print("Agent:再见!")
break
# 调用Agent处理输入
response = agent_executor.invoke({"input": user_input})
print(f"Agent:{response['output']}")
六、Callbacks
在 LangChain 中,Callbacks(回调) 是一套用于 实时监控、干预、记录 LangChain 流程(如 Chain 运行、Agent 工具调用、LLM 推理) 的核心机制。它允许开发者在关键节点(如 “LLM 开始生成”“工具调用前”“流程结束”)插入自定义逻辑,实现日志记录、性能监控、结果修改、用户交互等功能,是 LangChain 灵活性和可扩展性的重要体现。
一、Callbacks 的核心价值与应用场景
Callbacks 的本质是 “事件驱动的钩子(Hook)”——LangChain 在执行流程中会触发一系列预设 “事件”,开发者通过注册 “回调函数” 来响应这些事件。其核心应用场景包括:
二、LangChain 的核心事件与 Callback 类型
LangChain 定义了一套标准化的 “事件体系”,覆盖从 LLM 到 Agent 的全流程。不同组件(LLM、Chain、Agent、Tool)对应不同的事件,常见核心事件如下:
1. 通用事件(全组件适用)
2. LLM 专属事件
3. 工具调用专属事件
4. Agent 专属事件
5. Callback 类型分类
根据实现方式,LangChain 的 Callback 主要分为两类:
基础 Callback:继承
BaseCallbackHandler类,重写对应事件方法(如on_llm_start),自定义逻辑。集成 Callback:LangChain 内置的、与第三方工具集成的 Callback(如
FileCallbackHandler写入日志文件、WandbCallbackHandler对接 Weights & Biases 监控)。
基础 Callback - 日志记录(监控 Chain 全流程)
需求:记录 Chain 执行的每个关键节点(开始 / 结束 / 错误)、LLM 输入输出、工具调用参数,输出到控制台。
from langchain.callbacks.base import BaseCallbackHandler
from langchain.chains import ConversationChain
from langchain_community.chat_models import ChatOpenAI
from langchain.memory import ConversationBufferMemory
from datetime import datetime
# 1. 自定义 Callback 类:继承 BaseCallbackHandler,重写事件方法
class CustomLoggingCallback(BaseCallbackHandler):
def __init__(self):
self.start_time = None # 用于记录流程耗时
# -------------------------- 通用 Chain 事件 重写 --------------------------
def on_chain_start(self, serialized, inputs, **kwargs):
"""Chain 开始执行时触发"""
self.start_time = datetime.now()
chain_name = serialized.get("name", "UnknownChain") # 获取 Chain 名称
print(f"\n[{datetime.now()}] 🚀 {chain_name} 开始执行")
print(f"[输入参数]:{inputs}")
def on_chain_end(self, outputs, **kwargs):
"""Chain 执行结束时触发"""
duration = (datetime.now() - self.start_time).total_seconds() # 计算耗时
print(f"[{datetime.now()}] ✅ Chain 执行结束(耗时:{duration:.2f}s)")
print(f"[输出结果]:{outputs}")
def on_chain_error(self, error, **kwargs):
"""Chain 执行报错时触发"""
print(f"[{datetime.now()}] ❌ Chain 执行错误:{str(error)[:100]}")
# -------------------------- LLM 专属事件 --------------------------
def on_llm_start(self, serialized, prompts, **kwargs):
"""LLM 开始生成时触发"""
llm_name = serialized.get("name", "UnknownLLM")
print(f"[{datetime.now()}] 🧠 {llm_name} 开始生成(Prompt 前100字符):{prompts[0][:100]}...")
def on_llm_end(self, response, **kwargs):
"""LLM 生成结束时触发"""
llm_output = response.generations[0][0].text # 获取 LLM 输出
print(f"[{datetime.now()}] 📝 LLM 生成结束(输出前100字符):{llm_output[:100]}...")
# -------------------------- 工具调用事件 --------------------------
def on_tool_start(self, serialized, input_str, **kwargs):
"""工具开始调用时触发"""
tool_name = serialized.get("name", "UnknownTool")
print(f"[{datetime.now()}] 🔧 {tool_name} 开始调用(参数):{input_str}")
def on_tool_end(self, output, **kwargs):
"""工具调用结束时触发"""
print(f"[{datetime.now()}] 📤 工具调用结束(输出):{output}")
# 2. 初始化组件:LLM + Memory + Chain
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0.3)
memory = ConversationBufferMemory(memory_key="history")
# 3. 注册 Callback:创建 Chain 时通过 `callbacks` 参数传入
conversation_chain = ConversationChain(
llm=llm,
memory=memory,
verbose=False, # 关闭 LangChain 默认日志,使用自定义 Callback
callbacks=[CustomLoggingCallback()] # 注册自定义 Callback
)
# 4. 测试 Chain:触发 Callback 事件
conversation_chain.predict(input="介绍 LangChain 的 Callbacks 组件")输出效果:
[2024-05-20 15:30:00] 🚀 ConversationChain 开始执行
[输入参数]:{'input': '介绍 LangChain 的 Callbacks 组件', 'history': ''}
[2024-05-20 15:30:00] 🧠 ChatOpenAI 开始生成(Prompt 前100字符):The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific det...
[2024-05-20 15:30:02] 📝 LLM 生成结束(输出前100字符):LangChain 的 Callbacks(回调)是一套用于监控、干预和扩展 LangChain 流程的机制。它允许开发者在关键节点(如 LLM 生成、工具调用)插入自定义逻辑...
[2024-05-20 15:30:02] ✅ Chain 执行结束(耗时:2.15s)
[输出结果]:{'response': 'LangChain 的 Callbacks(回调)是一套用于监控、干预和扩展 LangChain 流程的机制...'}1