基于LangChain实现了一个简单的RAG脚手架:https://github.com/XuWink/SimpleRAG.git
随着通用大模型的快速发展,rag成为了其能够落地的一个重要组成。
检索增强生成(Retrieval-Augmented Generation,RAG)是解决大语言模型(LLM)知识局限的核心技术框架,通过 “检索外部知识 + 模型生成” 的协同模式,实现更精准、可控的内容输出
大语言模型(如 GPT-4、Llama 3)虽能生成流畅文本,但存在三大核心缺陷:知识局限于训练数据(无法覆盖 2025 年最新信息)、易产生 “幻觉”(虚构事实)、私有知识无法接入。RAG 通过 “先检索后生成” 的流程,相当于给 LLM 配备了 “外置知识库”,具体可类比人类工作场景:
检索环节:如同研究员查阅文献库,从外部知识库中快速定位与问题相关的信息片段;
生成环节:类似专家基于文献资料撰写报告,结合检索结果生成逻辑连贯的回答。
。
我们可以将RAG技术栈划分为四个模块:数据工程、效果评估、模型管理和高效代码设计。
一、数据工程
对数据的清洗,分割
向量数据库:存储文档向量的专用数据库,支持毫秒级相似性检索,主流工具包括 Chroma(轻量开源)、Pinecone(云端托管);
Embedding 模型:负责将文本转为向量,平衡语义准确性与计算效率,常用模型有 text-embedding-ada-002(OpenAI)、BGE-large;
检索算法:核心是计算向量相似度(Vector Similarity),常用余弦相似度(衡量向量方向一致性)和欧氏距离(衡量向量空间距离)。
二、评估效果
在大模型生成和查询的过程中,性能的损耗是不可避免的。如何优化,得到更好的性能是很重要的。
三、模型管理
接入各种大模型,可以调用厂商的API KEY,或者基于本地自己部署。
四、高效而稳定的代码设计
解决大模型幻觉的两种方式:
prompt提示词工程
RAG,检索增强生成
大模型微调,根据特定知识进行微调(成本高)
LangChain
(9 封私信 / 62 条消息) 一文详解最热的 LLM 应用框架 LangChain - 知乎
langchain是目前市场上最流行的rag开发框架之一。
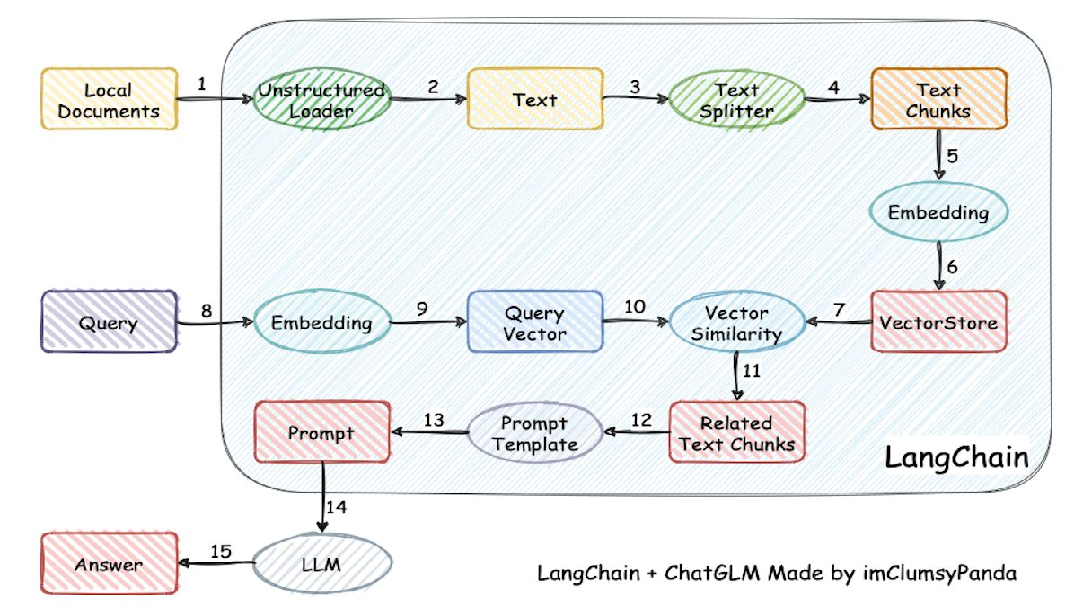
基于 LangChain 框架,严格遵循图中流程实现的 RAG(检索增强生成)完整代码,包含本地文档加载、文本分块、嵌入、向量存储、相似度检索、Prompt 构建和 LLM 调用等全流程
pip install langchain openai sentence_transformers tiktoken
pip install -U langchain-community
pip install langchain-chroma
pip install pypdf
pip install docx2txt python-multipart导入相关依赖:
from langchain.document_loaders import DirectoryLoader, TextLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings import OpenAIEmbeddings, HuggingFaceEmbeddings
from langchain.vectorstores import Chroma
from langchain.chains import RetrievalQA
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate一、Unstructured Loader
在进行RAG开发时,首先要对本地无结构知识进行数据清理。通常,我们的数据格式很丰富,包括txt, word,pdf, markdown, png, 甚至word里面包含图片,图片上又有文字,下面是使用langchain加载文本的示例:
def load_documents():
from langchain_community.document_loaders import (
DirectoryLoader, TextLoader, Docx2txtLoader,
UnstructuredMarkdownLoader, PyPDFium2Loader
)
loaders = [
# TXT 文档加载
DirectoryLoader(
DOCS_DIR, glob="**/*.txt",
loader_cls=TextLoader, loader_kwargs={"encoding": "utf-8"},
show_progress=True
),
# PDF 文档加载(PyPDFium2 比 PyPDF 更精准,支持中文)
DirectoryLoader(
DOCS_DIR, glob="**/*.pdf",
loader_cls=PyPDFium2Loader, show_progress=True
),
# DOCX 文档加载
DirectoryLoader(
DOCS_DIR, glob="**/*.docx",
loader_cls=Docx2txtLoader, show_progress=True
),
# Markdown 文档加载(补充 mode 参数,修复加载失败)
DirectoryLoader(
DOCS_DIR, glob="**/*.md",
loader_cls=UnstructuredMarkdownLoader,
loader_kwargs={"encoding": "utf-8", "mode": "single"}, # 单段落模式,避免拆分混乱
show_progress=True
),
]
documents = []
for loader in loaders:
try:
docs = loader.load()
for doc in docs:
doc.metadata["file_type"] = loader.loader_cls.__name__
# 补充文档路径简化(仅保留文件名,避免路径过长)
doc.metadata["source"] = Path(doc.metadata["source"]).name
print(f"✅ 成功加载 {len(docs)} 个 {loader.loader_cls.__name__} 文档")
documents.extend(docs)
except Exception as e:
error_msg = str(e)[:120] + "..." if len(str(e)) > 120 else str(e)
print(f"❌ {loader.loader_cls.__name__} 加载失败: {error_msg}")
print(f"\n📊 总计成功加载 {len(documents)} 个文档")
return documents
二、Text Splitter
文本划分:
def split_documents(documents):
from langchain.text_splitter import RecursiveCharacterTextSplitter
# 中文专属分隔符(优先按句拆分,其次按标点,最后按换行)
chinese_separators = [
"。", "!", "?", # 句末标点
";", ",", ":", # 句内标点
")", "】", "}", "》", # 右括号/右符号
"\n", " ", "" # 换行/空格/兜底
]
splitter = RecursiveCharacterTextSplitter(
chunk_size=CHUNK_SIZE,
chunk_overlap=CHUNK_OVERLAP,
separators=chinese_separators,
length_function=len # 中文按字符数计算长度(而非英文单词数)
)
chunks = splitter.split_documents(documents)
# 为每个分块添加唯一 ID(避免增量时重复)
for i, chunk in enumerate(chunks):
src = chunk.metadata.get("source", "unknown")
# 内容摘要(MD5 前 8 位)+ 文件名 + 序号,确保唯一性
content_digest = hashlib.md5(chunk.page_content.encode("utf-8")).hexdigest()[:8]
chunk.metadata["chunk_id"] = f"{src}_{i}_{content_digest}"
# 补充分块序号 metadata
chunk.metadata["chunk_index"] = i
print(f"✂️ 分块完成:共 {len(chunks)} 块(单块{CHUNK_SIZE}字,重叠{CHUNK_OVERLAP}字)")
return chunks三、Embedding
文本嵌入:
def init_embeddings():
from langchain_huggingface import HuggingFaceEmbeddings
# 检查本地模型是否存在
model_path = str(EMBEDDING_MODEL_PATH) if EMBEDDING_MODEL_PATH.exists() else EMBEDDING_MODEL_NAME
# 设备选择
device = "cuda" if torch.cuda.is_available() else "cpu"
if device == "cuda":
gpu_mem = torch.cuda.get_device_properties(0).total_memory / (1024 ** 3)
device = "cuda" if gpu_mem >= 4 else "cpu"
try:
# ✅ 核心修复:不再手动传 client,不再传 cache_folder
# langchain-huggingface 会自动处理缓存路径和模型加载
embeddings = HuggingFaceEmbeddings(
model_name=model_path,
model_kwargs={
"device": device,
"trust_remote_code": True,
},
encode_kwargs={
"normalize_embeddings": True, # BGE 必须归一化
"batch_size": 64,
"prompt": "为这个句子生成表示以用于检索相关文章:" # 新版用 `prompt` 替代 `query_instruction`
},
)
print(f"\n✅ Embedding 加载完成: {model_path}(设备:{device})")
return embeddings
except Exception as e:
error_msg = str(e)[:150] + "..." if len(str(e)) > 150 else str(e)
raise RuntimeError(f"Embedding 初始化失败: {error_msg}")四、VectorStore
文本向量数据库
def build_vector_db(chunks, embeddings):
from langchain_chroma import Chroma
# 检查向量库是否已存在
if VECTOR_DB_DIR and os.path.exists(VECTOR_DB_DIR):
print(f"\n🔍 检测到已存在向量库:{VECTOR_DB_DIR}")
# 加载现有向量库
vector_db = Chroma(
persist_directory=VECTOR_DB_DIR,
embedding_function=embeddings,
collection_metadata={"hnsw:space": "cosine"} # 使用 cosine 相似度
)
# 获取已存在的分块 ID
existing_ids = set(vector_db.get()["ids"])
new_chunks = [c for c in chunks if c.metadata["chunk_id"] not in existing_ids]
if new_chunks:
print(f"📈 增量添加 {len(new_chunks)} 个新分块...")
vector_db.add_documents(
documents=new_chunks,
ids=[c.metadata["chunk_id"] for c in new_chunks]
)
# ✅ 新版无需 .persist(),数据自动持久化
total_count = len(vector_db.get()["ids"])
print(f"✅ 增量完成:总计 {total_count} 条向量")
else:
total_count = len(existing_ids)
print(f"📊 无新增内容,当前共 {total_count} 条向量")
return vector_db
# 新建向量库
print(f"\n🆕 创建新向量库:{VECTOR_DB_DIR}")
vector_db = Chroma.from_documents(
documents=chunks,
embedding=embeddings,
persist_directory=VECTOR_DB_DIR,
ids=[c.metadata["chunk_id"] for c in chunks],
collection_metadata={"hnsw:space": "cosine"} # 使用 HNSW 索引 + 余弦距离
)
print(f"✅ 新向量库构建完成,共 {len(chunks)} 条向量")
return vector_db五、Query
def init_llm():
from transformers import AutoTokenizer, AutoModelForCausalLM, pipeline
from langchain_community.llms import HuggingFacePipeline
from accelerate import Accelerator # 优化 GPU 资源分配
# 优先使用本地缓存模型
model_path = str(LLM_MODEL_PATH) if LLM_MODEL_PATH.exists() else LLM_MODEL_NAME
print(f"\n🔄 正在加载 LLM:{model_path}")
# 初始化 Tokenizer(解决中文分词问题)
try:
tokenizer = AutoTokenizer.from_pretrained(
model_path,
trust_remote_code=True,
use_fast=False, # 禁用 fast tokenizer,避免中文分词错误
padding_side="right", # 右填充(避免生成时警告)
cache_dir=str(MODEL_BASE_DIR.resolve())
)
# 补充 Tokenizer 缺失的特殊 token
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token # 用 eos_token 作为 pad_token
if tokenizer.unk_token is None:
tokenizer.unk_token = tokenizer.eos_token
print("✅ Tokenizer 加载完成")
except Exception as e:
raise RuntimeError(f"Tokenizer 加载失败: {str(e)[:100]}")
# 4bit 量化配置(显存优化核心,7B 模型 4bit 约占 5~6GB 显存)
model_kwargs = {
"torch_dtype": torch.float16, # 半精度,平衡精度与显存
"device_map": "auto", # 自动分配设备(GPU 优先,不足则用 CPU)
"trust_remote_code": True,
"low_cpu_mem_usage": True, # 低 CPU 内存占用
"cache_dir": str(MODEL_BASE_DIR.resolve()),
# 4bit 量化参数(bitsandbytes 实现)
"load_in_4bit": True,
"bnb_4bit_quant_type": "nf4", # 归一化浮点(更适合语义任务)
"bnb_4bit_compute_dtype": torch.float16,
"bnb_4bit_use_double_quant": True # 双重量化(进一步减少显存)
}
# CPU 环境不支持 4bit,移除量化参数
if not torch.cuda.is_available():
for k in ["load_in_4bit", "bnb_4bit_quant_type", "bnb_4bit_compute_dtype", "bnb_4bit_use_double_quant"]:
model_kwargs.pop(k, None)
model_kwargs["torch_dtype"] = torch.float32 # CPU 用单精度
print("⚠️ 未检测到 GPU,使用 CPU 运行 LLM(速度较慢,建议用 3B 模型)")
# 构建 LLM Pipeline 的工具函数
def _build_llm_pipeline(_model):
text_gen_pipeline = pipeline(
"text-generation",
model=_model,
tokenizer=tokenizer,
max_new_tokens=512, # 生成回答的最大长度
temperature=0.3, # 随机性(0.1~0.5 适合问答,越低越严谨)
top_p=0.9, # 采样阈值(过滤低概率词)
repetition_penalty=1.15, # 重复惩罚(避免生成重复内容)
return_full_text=False, # 仅返回生成的回答(不包含 prompt)
do_sample=True, # 采样生成(提升回答多样性)
pad_token_id=tokenizer.pad_token_id,
eos_token_id=tokenizer.eos_token_id
)
# 封装为 LangChain 兼容的 LLM
return HuggingFacePipeline(pipeline=text_gen_pipeline)
# 尝试加载 LLM(4bit → 8bit → 全精度 自动降级)
try:
print("🔧 尝试 4bit 量化加载 LLM...")
model = AutoModelForCausalLM.from_pretrained(model_path, **model_kwargs)
quant_mode = "4bit"
except Exception as e1:
print(f"⚠️ 4bit 加载失败,降级为 8bit:{str(e1)[:80]}")
# 8bit 配置(显存约 8~10GB)
model_kwargs_8bit = model_kwargs.copy()
model_kwargs_8bit.pop("load_in_4bit", None)
model_kwargs_8bit.pop("bnb_4bit_quant_type", None)
model_kwargs_8bit.pop("bnb_4bit_compute_dtype", None)
model_kwargs_8bit.pop("bnb_4bit_use_double_quant", None)
model_kwargs_8bit["load_in_8bit"] = True
try:
model = AutoModelForCausalLM.from_pretrained(model_path, **model_kwargs_8bit)
quant_mode = "8bit"
except Exception as e2:
print(f"⚠️ 8bit 加载失败,降级为全精度(CPU/GPU):{str(e2)[:80]}")
# 全精度配置(GPU 需 ≥14GB 显存,CPU 需 ≥24GB 内存)
model_kwargs_full = model_kwargs.copy()
for k in ["load_in_4bit", "load_in_8bit", "bnb_4bit_quant_type", "bnb_4bit_compute_dtype", "bnb_4bit_use_double_quant"]:
model_kwargs_full.pop(k, None)
try:
model = AutoModelForCausalLM.from_pretrained(model_path, **model_kwargs_full)
quant_mode = "全精度"
except Exception as e3:
raise RuntimeError(f" LLM 加载失败:{str(e3)[:100]}")
# 构建 LLM Pipeline 并返回
llm = _build_llm_pipeline(model)
# 打印 LLM 加载状态(设备 + 量化模式)
device_info = model.device if hasattr(model, 'device') else "unknown"
print(f"✅ LLM 加载完成(设备:{device_info},量化:{quant_mode})")
return llm六、Answer
编写prompt
PROMPT_TEMPLATE = """你是专业的中文问答助手,严格遵循以下规则:
1. 仅使用【上下文】中的信息回答问题,不添加任何外部知识或主观推测;
2. 若【上下文】中没有与问题相关的内容,直接回答:“根据提供的知识库,无法回答该问题”;
3. 回答需简洁准确,用中文口语化表达,避免冗长或生硬的表述;
4. 若问题涉及多个要点,分点回答(用数字序号),但不要过度展开。
【上下文】
{context}
【问题】
{query}
【回答】
"""rag:
def rag_pipeline(query, vector_db, llm):
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
print(f"\n🔍 正在检索与「{query}」相关的内容(Top {TOP_K},阈值 {DISTANCE_THRESHOLD})...")
# 检索逻辑:支持 MMR 去冗 / 普通相似度过滤
if USE_MMR:
# MMR(Maximal Marginal Relevance):平衡相关性与多样性,避免重复
retriever = vector_db.as_retriever(
search_type="mmr",
search_kwargs={
"k": TOP_K,
"fetch_k": max(20, TOP_K * 4), # 先召回更多候选,再筛选多样性
"lambda_mult": 0.5 # 0.0=仅相关性,1.0=仅多样性
}
)
relevant_docs = retriever.get_relevant_documents(query)
# MMR 无距离分数,用占位符标记
docs_with_score = [(doc, "MMR") for doc in relevant_docs]
else:
# 普通相似度检索:先召回更多候选,再按距离阈值过滤
raw_docs = vector_db.similarity_search_with_score(
query, k=max(20, TOP_K * 4) # 先召回 20 条(避免漏检)
)
# 按距离阈值过滤(余弦距离越小越相似,仅保留 < DISTANCE_THRESHOLD 的结果)
docs_with_score = [(d, s) for (d, s) in raw_docs if s < DISTANCE_THRESHOLD][:TOP_K]
# 打印检索结果(方便调试)
print("\n📄 检索到的相关片段:")
if not docs_with_score:
print("(未找到符合阈值的相关片段,建议检查问题表述或提高 DISTANCE_THRESHOLD)")
context = ""
else:
for i, (doc, score) in enumerate(docs_with_score, 1):
# 提取文档元数据(来源、分块序号)
source = doc.metadata.get("source", "未知文件")
chunk_idx = doc.metadata.get("chunk_index", "未知")
# 内容预览(截取前 120 字符,避免输出过长)
content_preview = doc.page_content[:120] + "..." if len(doc.page_content) > 120 else doc.page_content
# 打印格式区分 MMR 和普通检索
if score == "MMR":
print(f" {i}. 来源:{source}(分块 {chunk_idx}) | 内容:{content_preview}")
else:
# 计算相似度(余弦距离 → 相似度:1 - 距离,范围 0~1)
similarity = max(0.0, 1 - float(score))
print(f" {i}. 相似度:{similarity:.4f} | 来源:{source}(分块 {chunk_idx}) | 内容:{content_preview}")
# 组装上下文(拼接所有相关片段的内容)
context = "\n\n".join([doc.page_content for doc, _ in docs_with_score])
# 上下文长度限制(避免超过 LLM 上下文窗口,DeepSeek-7B 上下文窗口为 8192)
if len(context) > 6000: # 预留 2000+ 长度给 prompt 和回答
context = context[:6000] + "\n...(上下文过长,已截断关键部分)"
# 构建 Prompt 并生成回答
prompt = PromptTemplate(template=PROMPT_TEMPLATE, input_variables=["context", "query"])
chain = LLMChain(llm=llm, prompt=prompt)
try:
print(f"\n🧠 正在生成回答(基于 {len(docs_with_score)} 个相关片段)...")
answer = chain.run({"context": context, "query": query}).strip()
# 清理回答中的多余空行
answer = "\n".join([line.strip() for line in answer.split("\n") if line.strip()])
return answer
except Exception as e:
error_msg = str(e)[:160] + "..." if len(str(e)) > 160 else str(e)
return f"❌ 回答生成失败:{error_msg}\n建议检查:1) LLM 模型是否正常加载 2) 显存/内存是否充足"
# ========================== 8. CLI 主入口(友好交互 + 异常处理) ==========================
def main():
# 检查文档目录是否存在,不存在则创建
docs_path = Path(DOCS_DIR)
docs_path.mkdir(exist_ok=True)
print(f"📁 文档目录:{docs_path.resolve()}(请将 TXT/PDF/DOCX/MD 文档放入该文件夹)")
# 步骤 1:加载文档
try:
documents = load_documents()
except Exception as e:
print(f"\n❌ 文档加载失败:{str(e)[:100]}")
print("💡 建议:检查文档目录权限、文档格式是否正常(避免加密/损坏文件)")
return
# 无文档时提示退出
if not documents:
print("❗ 未加载到任何文档,请在 'knowledge_base' 文件夹中放入有效文档后重试")
return
# 步骤 2:文档分块
try:
chunks = split_documents(documents)
except Exception as e:
print(f"\n❌ 文档分块失败:{str(e)[:100]}")
print("💡 建议:检查文档内容是否有特殊字符,或调整 CHUNK_SIZE/CHUNK_OVERLAP 参数")
return
# 步骤 3:初始化 Embedding(支持镜像回退)
try:
embeddings = init_embeddings()
except Exception as e:
print(f"\n⚠️ Embedding 加载失败,尝试回退到 Hugging Face 官方源:{str(e)[:100]}")
# 回退官方源(删除镜像环境变量)
if "HF_ENDPOINT" in os.environ:
del os.environ["HF_ENDPOINT"]
try:
embeddings = init_embeddings()
except Exception as e2:
print(f"\n❌ 回退官方源后仍失败:{str(e2)[:100]}")
print("💡 建议:1) 检查网络是否能访问 huggingface.co 2) 手动下载模型到 models 目录")
return
# 步骤 4:构建/加载向量库
try:
vector_db = build_vector_db(chunks, embeddings)
except Exception as e:
print(f"\n❌ 向量库构建失败:{str(e)[:100]}")
print("💡 建议:1) 删除 chroma_vector_db 文件夹后重试 2) 检查磁盘空间是否充足")
return
# 步骤 5:初始化 LLM
try:
llm = init_llm()
except Exception as e:
print(f"\n❌ LLM 加载失败:{str(e)[:100]}")
print("💡 建议:1) 若用 GPU,确保显存 ≥8GB(4bit)/10GB(8bit) 2) CPU 环境建议改用 3B 模型(如 deepseek-ai/deepseek-llm-3b-chat) 3) 检查模型下载是否完整")
return
# 步骤 6:启动问答交互
print("\n" + "=" * 60)
print("💬 RAG 中文智能问答系统已就绪")
print("📌 操作说明:输入问题即可查询,输入 'q'/'quit'/'退出' 结束程序")
print("=" * 60)
# 交互循环
while True:
try:
user_query = input("\n请输入你的问题:").strip()
except (EOFError, KeyboardInterrupt):
# 捕获 Ctrl+C/ Ctrl+D 退出信号
print("\n👋 程序已正常退出,欢迎下次使用!")
break
# 退出逻辑
if user_query.lower() in ["q", "quit", "exit", "退出"]:
print("👋 程序已正常退出,欢迎下次使用!")
break
# 空输入处理
if not user_query:
print("⚠️ 请输入有效的问题,不能为空!")
continue
# 生成回答并打印
answer = rag_pipeline(user_query, vector_db, llm)
print(f"\n📝 回答结果:\n{answer}")
print("\n" + "-" * 40) # 分隔线,提升可读性
# 程序入口(捕获全局异常)
if __name__ == "__main__":
try:
main()
except Exception as e:
print(f"\n❌ 程序运行出错:{str(e)}")
print("\n💡 排查清单:")
print("1. 依赖包是否安装完整:执行 pip install -r requirements.txt(见下方说明)")
print("2. 模型下载是否完整:检查 models 目录下是否有 BGE 和 DeepSeek 模型文件")
print("3. 硬件资源是否充足:GPU 显存 ≥8GB(4bit)/ CPU 内存 ≥24GB(全精度)")
print("\n📌 推荐依赖版本(requirements.txt 内容):")
print("langchain==0.2.10\nlangchain-community==0.2.10\nlangchain-huggingface==0.1.0")
print("chromadb==0.5.17\nsentence-transformers==2.7.0\ntransformers==4.41.1")
print("accelerate==0.30.1\nbitsandbytes==0.43.0\ntorch==2.2.2\npypdfium2==4.27.0")
print("docx2txt==0.8\funstructured==0.14.9")总结
流程对应说明(与图中步骤一一对应)
Local Documents → Unstructured Loader:通过
DirectoryLoader加载本地文件夹(如docs)中的所有文本文件。Unstructured Loader → Text:
loader.load()将文档转为 LangChain 的Document对象,包含文本内容和元数据。Text → Text Splitter:
RecursiveCharacterTextSplitter按递归字符规则将长文本切分为多个小文本块(text_chunks)。Text Splitter → Text Chunks:分块后得到列表
text_chunks,每个元素是独立的文本片段。Text Chunks → Embedding:
embeddings.embed_documents(或embed_query)将文本块转为向量表示。Embedding → VectorStore:
Chroma.from_documents将文本块和对应向量存入 Chroma 向量数据库。VectorStore ← Query 侧流程:用户查询(
user_query)同样要经过嵌入和相似度检索。Query → Embedding:
embeddings.embed_query(user_query)将用户问题转为向量。Embedding → Query Vector:得到查询的向量表示
query_embedding。Query Vector → Vector Similarity:
vector_store.similarity_search_with_score计算查询向量与向量库中所有向量的相似度。Vector Similarity → Related Text Chunks:返回 TopK 最相似的文本块
related_chunks。Related Text Chunks → Prompt Template:将相关文本块拼接为
context,代入PromptTemplate生成最终 Prompt。Prompt Template → Prompt:生成包含上下文和问题的完整 Prompt(
final_prompt)。Prompt → LLM:将 Prompt 传入大语言模型(
llm)。LLM → Answer:LLM 基于 Prompt 生成最终答案(
answer)。
七、代码
https://github.com/XuWink/SimpleRAG.git
git clone https://github.com/XuWink/SimpleRAG.git
git checkout master